Community Survey Data Part 3 - Blockers
In the first two posts we looked at why surveys are hard and where we see burnout. Now let’s try another question - what blocks people, and how does it show itself in the ratings?
What are the blockers?
This is a tricky question, and I may well redesign it in future surveys. For now, it is a ranking question. We ask people to rate these blockers in order of how frequently they encounter them, with “rank 1” being the most frequent and “rank 5” the least - we also allow an NA for any rank to say this one does not affect them at all. The blockers are:
- Not having enough time to contribute
- Unwanted steps in the process (e.g. writing tests/docs)
- Confusing process, hard to follow how to contribute
- Slow reviews from maintainers
- Unpleasantness from other community members
This results in a table - one column per blocker, and one row per respondent with numbers 1-5 and perhaps some NAs too.
We’ll treat it like this:
- Add NA in as level 6 - if rank 5 is the “least affected” level, then by definition the only thing better than “least affected” is “not affected”.
- Invert the order. We expect any of these to have a negative effect how people about the community. To make the maths work, we want the worst option to have the highest value (so we get a negative correlation with rating, if any)
Now we can do some modeling!
More models
Given the number of predictors here, we’re only going to look at “main effects” - that is, how each one affects Rating. It’s plausible that there are some interactions (I can definitely see a case for Slow Reviews interacting with Not Enough Time), but I didn’t have time to do all the possible combinations (there are many).
Likewise, it’s hard to visualise this one in total, as there are many categories - 5 blockers, 6 levels for each blocker, 5 ratings to affect. So we can;t just do a single plot. We can pick one and view it:
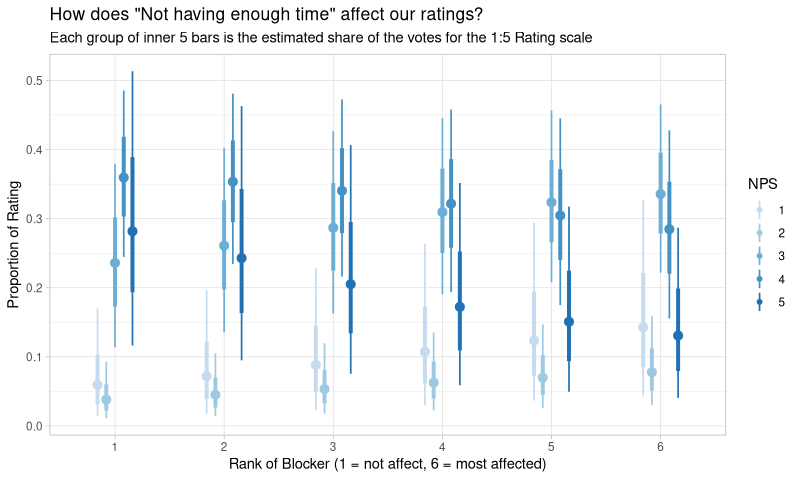
OK, so we can sort-of see an effect there - as you might as expect, when the blocker affects people more (higher values equal higher ranking), the ratings go down. But this would be tedious to study for every blocker individually. Let’s skip straight to the coefficient plot:
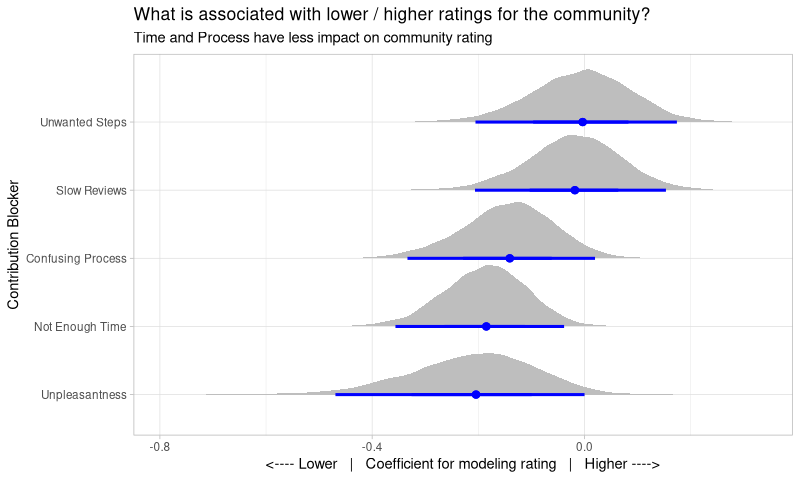
So, just like last time, we’re seeing the plausible values for the modeling coefficients of each blocker. This is not a look at how prevalent a blocker is in our community, but rather how bad that blocker is when present at all.
Right away, we can see a few things. Firstly, none are strongly positive - we expect that. Presence of blockers should not increase ratings, so this is a comforting result, and suggests the model is fine.
Second, “Unpleasantness” is the worst, as we would expect, but not by much - that does surprise me, as I expected this to be strongly negative. The width of it’s distribution is interesting too - some of that is driven by a lower sample size (not many people were affected by it at all), but it also speaks to a large variance in how people tolerate it. Note, I’m not advocating that we allow bad behaviour at all, I’m only noting that it’s impact is quite varied.
Third, “Unwanted Steps” and “Slow Reviews” are close to zero, which suggests that contributors don’t view these too badly, even when they’re strongly affected by them. Perhaps this is just seen as part of the nature of open source? Again, we should fix this where we can (especially as there is likely an interaction with “Not Enough Time”), but with limited resources it’s useful to know what to tackle first.
Action points?
There’s not really a course of action to take here, this is more about understanding the impact of problems when we encounter them in future. That said, seeing “Unpleasantness” and “Not Enough Time” at the bottom suggests to me that our policy of making contribution easy, and having clear conduct policies, is the right way to go, as these have the most impact.
Coda
If you’ve read this far (all three posts? Goodness, you have stamina) then thanks! If you have other things you think I should look at in our data (or you want to see my code), let me know!